Prerequisites
In this article you'll learn:
The Loop node allows you to process arrays and lists from previous nodes one item at a time. This is particularly useful when you have data from an API or database query that returns multiple records, and you want to process each record individually in subsequent nodes.
The Loop node can only be used in scheduled background data pipelines, not in real-time flows. This means it cannot be used in flows that are triggered by user actions or real-time events. It is designed for batch processing scenarios where you want to handle multiple items in a list sequentially.
The Loop node takes an array from your input data and outputs each item in the array individually. When the flow runs, subsequent nodes will be executed once for each item in the array.
For example, if your previous node returns an array with 5 items, the nodes after the Loop node will run 5 times - once for each item.
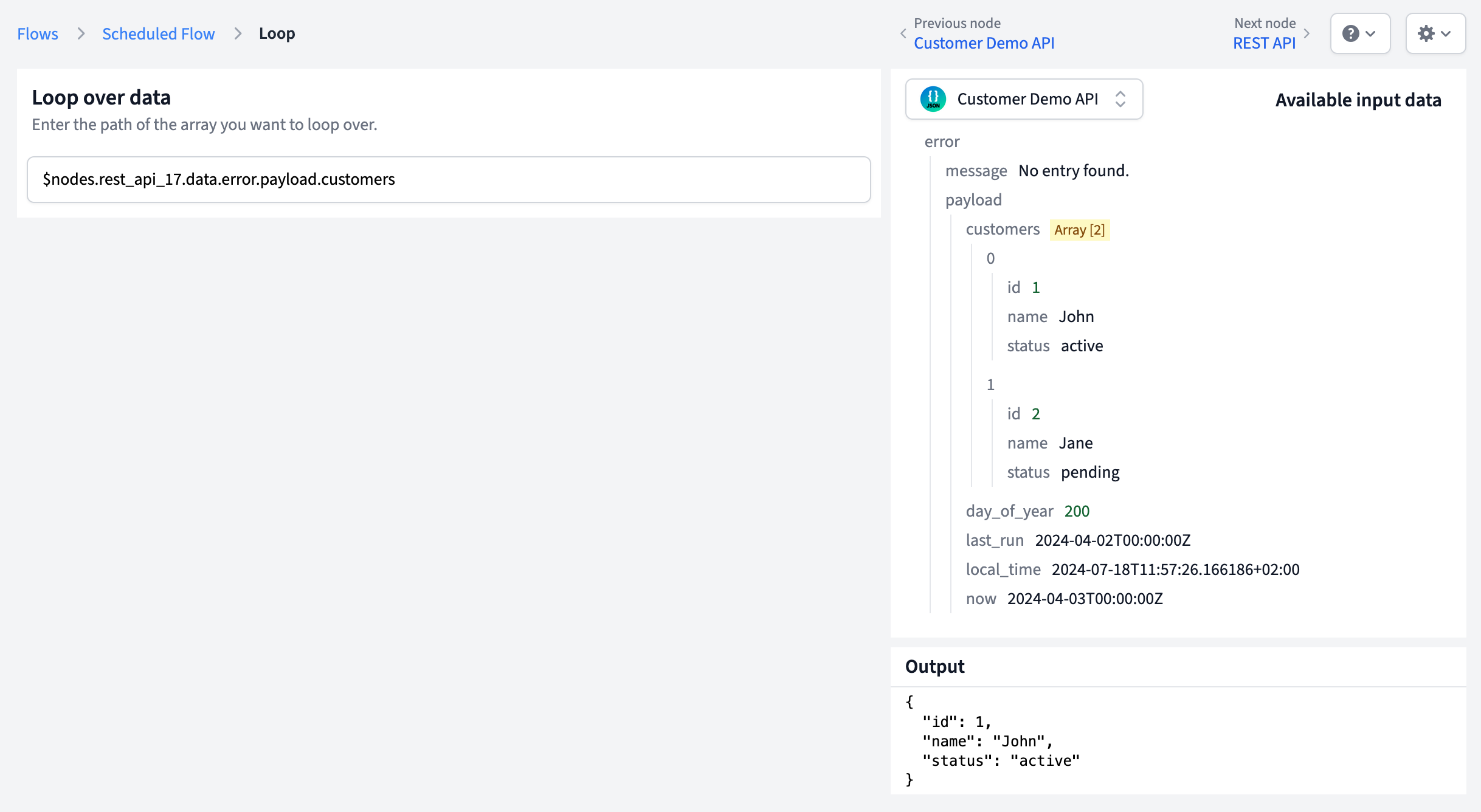
The Loop node has a simple configuration: you need to specify the path to the array in your input data.
In the configuration field, enter the path to the array using placeholder syntax. For example:
$data - if the entire input is an array$data.customers - if there's a "customers" array in your data$data.results.items - for nested arraysAPI response with multiple records:
{
"results": [
{"id": 1, "name": "John", "email": "john@example.com"},
{"id": 2, "name": "Jane", "email": "jane@example.com"},
{"id": 3, "name": "Bob", "email": "bob@example.com"}
]
}
Path: $data.results
Database query returning multiple rows:
[
{"customer_id": 123, "order_total": 99.99},
{"customer_id": 456, "order_total": 149.50},
{"customer_id": 789, "order_total": 75.25}
]
Path: $data
To test your Loop node, you need input data that contains an array.
The Input data is displayed as individual editable fields in the Preview box. When you have a previous node in your flow, the output data from that node automatically appears as the test input data for the current node. You can edit each field value individually to test different scenarios.
If this is the first node in your flow (connected directly to a trigger), the test input data will be populated with the data captured from your trigger.
Example test data:
{
"customers": [
{"id": 1, "name": "John", "status": "active"},
{"id": 2, "name": "Jane", "status": "pending"}
]
}
The Loop node outputs individual items from the array. In preview mode, you'll see only the first item. When the flow runs, each item will be processed separately.
Input array:
[
{"id": 1, "name": "John"},
{"id": 2, "name": "Jane"},
{"id": 3, "name": "Bob"}
]
Loop node output (per iteration):
{"id": 1, "name": "John"}
Then:
{"id": 2, "name": "Jane"}
And so on...
When an API returns multiple records, use the Loop node to process each record individually:
Process multiple database records one by one:
SELECT * FROM pending_ordersTransform each item in a list:
If the path you specify doesn't point to a valid array, the Loop node will not run and will abort the data pipeline.
Make sure your path correctly references an array in your input data structure.
Keep in mind that using a Loop node will cause subsequent nodes to run multiple times. If you're processing a large array (hundreds or thousands of items), this could impact performance and may hit rate limits on external APIs.
For large datasets, consider: